
安卓面试重点

安卓面试重点
曦臣1. 安卓四大组件
- Activity
- service
- broadcast Receiver
- content Provider
2. Activity的生命周期
onCreate() => onStart() => onResume() => onPause() => onStop() =>onRestart()=> onDestrory()
按home键返回桌面后再次进入生命周期是什么样的?
- 启动:onCreat->onStart->onResume
- HOME键的执行顺序:onPause->onStop->onRestart->onStart->onResume
下面的不用
- BACK键的顺序: onPause->onStop->onDestroy->onCreate->onStart->onResume
生命周期具体场景示例
- 启动Activity:系统会先调用onCreate方法,然后调用onStart方法,最后调用onResume,Activity进入运行状态。
- 当前Activity被其他Activity覆盖其上或被锁屏:系统会调用onPause方法,暂停当前Activity的执行。
- 当前Activity由被覆盖状态回到前台或解锁屏:系统会调用onResume方法,再次进入运行状态。
- 当前Activity转到新的Activity界面或按Home键回到主屏,自身退居后台:系统会先调用onPause方法,然后调用onStop方法,进入停滞状态。
- 用户后退回到此Activity:系统会先调用onRestart方法,然后调用onStart方法,最后调用onResume方法,再次进入运行状态。
- 当前Activity处于被覆盖状态或者后台不可见状态,即第2步和第4步,系统内存不足,杀死当前Activity,而后用户退回当前Activity:再次调用onCreate方法、onStart方法、onResume方法,进入运行状态。
- 用户退出当前Activity:系统先调用onPause方法,然后调用onStop方法,最后调用onDestory方法,结束当前Activity
3. Fragment的生命周期
onAttach() => oncreate() => onCreateView() => onActivityCreate() => onDestroyView() => onDetach()
4. service 的生命周期,两种启动方式的区别
startService
onCreate() -> onStartCommand() -> onDestroy()
bindService
onCreate() -> onbind() -> onUnbind()-> onDestroy()
区别
启动
如果服务已经开启,多次执行startService不会重复的执行onCreate(), 而是会调用onStart()和 onStartCommand()。
如果服务已经开启,多次执行bindService时,onCreate和onBind方法并不会被多次调用
销毁
当执行stopService时,直接调用onDestroy方法
调用者调用unbindService方法或者调用者Context不存在了(如Activity被finish了),Service就会调用 onUnbind->onDestroy
使用startService()方法启用服务,调用者与服务之间没有关连,即使调用者退出了,服 务仍然运行。
使用bindService()方法启用服务,调用者与服务绑定在了一起,调用者一旦退出,服务也就终止。
1、单独使用startService & stopService
(1)第一次调用startService会执行onCreate、onStartCommand。
(2)之后再多次调用startService只执行onStartCommand,不再执行onCreate。
(3)调用stopService会执行onDestroy。
2、单独使用bindService & unbindService
(1)第一次调用bindService会执行onCreate、onBind。
(2)之后再多次调用bindService不会再执行onCreate和onBind。
(3)调用unbindService会执行onUnbind、onDestroy。
5. Activity的四种启动模式
- standard(标准模式):如果在mainfest中不设置就默认standard。standard就是新建一个Activity就在栈中新建一个activity实例;
- singleTop(栈顶复用模式):与standard相比栈顶复用可以有效减少activity重复创建对资源的消耗,但是这要根据具体情况而定,不能一概而论;
- singleTask(栈内单例模式):栈内只有一个activity实例,栈内已存activity实例,在其他activity中start这个activity,Android直接把这个实例上面其他activity实例踢出栈GC掉;
- singleInstance(堆内单例) :整个手机操作系统里面只有一个实例存在就是内存单例;如APP经常调用的拨打电话、系统通讯录、系统Launcher、锁屏键、来电显示等系统应用。singleInstance适合需要与程序分离开的页面。例如闹铃提醒,将闹铃提醒与闹铃设置分离。
在singleTop、singleTask、singleInstance 中如果在应用内存在Activity实例,并且再次发生startActivity(Intent intent)回到Activity后,由于并不是重新创建Activity而是复用栈中的实例,因此Activity再获取焦点后并没调用onCreate、onStart,而是直接调用了onNewIntent(Intent intent)函数。
6. 进程,线程,协程的关系
进程(Process)、线程(Thread)和协程(Coroutine)都是计算机科学中用于管理和执行任务的概念,它们之间有一些相似性和区别。
- 进程(Process):
- 进程是操作系统分配资源的基本单位,每个进程都有独立的内存空间和执行环境。
- 进程之间相互独立,彼此之间不能直接访问彼此的内存空间,通信需要通过特定的机制,比如进程间通信(IPC)。
- 每个进程都拥有独立的地址空间,包括代码、数据和堆栈,因此进程之间的切换开销相对较大。
- 线程(Thread):
- 线程是进程内的执行单元,多个线程可以共享同一个进程的资源,如内存空间和文件句柄。
- 同一进程内的线程之间可以直接访问共享的内存空间,因此线程间通信相对简单,但需要注意同步和互斥。
- 线程共享进程的地址空间,因此线程之间的切换开销相对较小。
- 协程(Coroutine):
- 协程是一种用户态的轻量级线程,它可以在执行过程中暂停和恢复,而不是像线程那样被操作系统调度。
- 协程可以避免创建大量线程的开销,提高并发程序的性能和可读性。
- 协程通常是由程序员显式地控制调度,而不是依赖于操作系统的线程调度器。
- 协程通常使用异步编程模式来实现非阻塞的并发操作,例如在 I/O 操作中等待结果而不阻塞线程。
关于它们的关系:
- 一个进程可以包含多个线程,这些线程共享该进程的资源,但彼此之间相对独立。
- 协程通常运行在线程之上,一个线程可以包含多个协程,但协程之间也是相对独立的,它们可以在需要时挂起和恢复。
7. Handler机制
说到 Handler,就不得不提与之密切相关的这几个类:Message、MessageQueue,Looper。
- Message:Message 中有两个成员变量值得关注:target 和 callback。
- target 其实就是发送消息的 Handler 对象
- callback 是当调用
handler.post(runnable)时传入的 Runnable 类型的任务。post 事件的本质也是创建了一个 Message,将我们传入的这个 runnable 赋值给创建的Message的 callback 这个成员变量。
- MessageQueue: 消息队列很明显是存放消息的队列,值得关注的是 MessageQueue 中的
next()方法,它会返回下一个待处理的消息。 - Looper:Looper 消息轮询器其实是连接 Handler 和消息队列的核心。如果想要在一个线程中创建一个 Handler,首先要通过
Looper.prepare()创建 Looper,之后还得调用Looper.loop()开启轮询。- **
prepare()**: 这个方法做了两件事:首先通过ThreadLocal.get()获取当前线程中的Looper,如果不为空,则会抛出一个RunTimeException,意思是一个线程不能创建2个Looper。如果为null则执行下一步。第二步是创建了一个Looper,并通过ThreadLocal.set(looper)。将我们创建的Looper与当前线程绑定。这里需要提一下的是消息队列的创建其实就发生在Looper的构造方法中。 - **
loop()**: 这个方法开启了整个事件机制的轮询。它的本质是开启了一个死循环,不断的通过MessageQueue的next()方法获取消息。拿到消息后会调用msg.target.dispatchMessage()来做处理。其实我们在说到 Message 的时候提到过,msg.target其实就是发送这个消息的 handler。这句代码的本质就是调用handler的dispatchMessage()。
- **
- Handler:Handler 的分析着重在两个部分:发送消息和处理消息。
- 发送消息:其实发送消息除了 sendMessage 之外还有 sendMessageDelayed 和 post 以及 postDelayed 等等不同的方式。但它们的本质都是调用了 sendMessageAtTime。在 sendMessageAtTime 这个方法中调用了 enqueueMessage。在 enqueueMessage 这个方法中做了两件事:通过
msg.target = this实现了消息与当前 handler 的绑定。然后通过queue.enqueueMessage实现了消息入队。 - 处理消息: 消息处理的核心其实就是
dispatchMessage()这个方法。这个方法里面的逻辑很简单,先判断msg.callback是否为 null,如果不为空则执行这个 runnable。如果为空则会执行我们的handleMessage方法。
- 发送消息:其实发送消息除了 sendMessage 之外还有 sendMessageDelayed 和 post 以及 postDelayed 等等不同的方式。但它们的本质都是调用了 sendMessageAtTime。在 sendMessageAtTime 这个方法中调用了 enqueueMessage。在 enqueueMessage 这个方法中做了两件事:通过
8. MVP、MVC、MVVM 架构模式
在 Android 开发中,MVP(Model-View-Presenter)、MVC(Model-View-Controller)和 MVVM(Model-View-ViewModel)是常用的架构模式,它们都旨在帮助开发者组织代码、提高代码的可读性和可维护性。以下是它们的简要介绍:
- MVP(Model-View-Presenter):
- MVP 是一种经典的架构模式,将应用程序分为三个主要部分:Model、View 和 Presenter。
- Model 表示数据模型或业务逻辑,View 表示用户界面,Presenter 作为 View 和 Model 之间的中介,负责处理业务逻辑和更新视图。
- 在 MVP 中,View 通常是 passively(被动的),它只负责展示数据和将用户输入传递给 Presenter;Presenter 负责处理用户输入、更新 View 和与 Model 进行交互。
- MVC(Model-View-Controller):
- MVC 是另一种经典的架构模式,也将应用程序分为三个部分:Model、View 和 Controller。
- Model 表示数据和业务逻辑,View 表示用户界面,Controller 负责处理用户输入、更新 Model 和 View。
- 在 Android 中,MVC 的实现方式可能会有所不同,通常是 Activity 或 Fragment 充当 Controller,负责协调 Model 和 View。
- MVVM(Model-View-ViewModel):
- MVVM 是一种相对较新的架构模式,它将应用程序分为三个部分:Model、View 和 ViewModel。
- Model 表示数据和业务逻辑,View 表示用户界面,ViewModel 作为 View 和 Model 之间的中介,负责管理视图的状态、处理用户输入和更新 Model。
- ViewModel 通常通过数据绑定库(如 Android Architecture Components 中的 LiveData 和 DataBinding)与 View 进行绑定,使 View 在 ViewModel 的状态变化时自动更新。
每种架构模式都有其优点和适用场景,选择合适的架构模式取决于项目的需求、团队的技术水平和个人偏好。MVP 适合需要测试和解耦的项目,MVC 适用于简单的项目,而 MVVM 则适用于需要利用数据绑定和响应式编程的项目。
9. RecyclerView
1.具有多久缓存机制
2.滑动回收复用机制
3.刷新回收复用机制
4.具有预布局的效果
ListView 和RecyclerView的区别
布局效果
ListView 的布局比较单一,只有一个纵向效果; RecyclerView 的布局效果丰富, 可以在 LayoutMananger 中 设置:线性布局(纵向,横向),表格布局,瀑布流布局
局部刷新
RecyclerView中可以实现局部刷新,例如:notifyItemChanged(); 如果要在ListView实现局部刷新,依然是可以实现的,当一个item数据刷新时,我们可以在Adapter中,实现一 个notifyItemChanged()方法,在方法里面通过这个 item 的 position,刷新这个item的数据
缓存区别
ListView有两级缓存,在屏幕与非屏幕内。 RecyclerView比ListView多两级缓存 ListView缓存View。 RecyclerView缓存RecyclerView.ViewHolder
用过listView和recyclerview吗?有什么优化的地方
优化方面:
- ListView中的getView方法中复用contentView:
- 在ListView的getView方法中,可以通过convertView参数来重用已经存在的视图,以减少内存消耗和提高性能。如果convertView不为null,可以直接对其进行重用,而不是每次都创建新的视图。
- RecyclerView避免重复创建点击事件:
- 在RecyclerView中,可以在ViewHolder中为itemView设置点击事件,而不是在每次绑定数据时都创建新的点击事件监听器。这样可以减少内存消耗,并提高性能。
- 布局优化:
- 在布局方面,尽量减少嵌套层级,使用相对布局或者约束布局等能够提高布局性能的布局方式。另外,避免使用过多的复杂布局和不必要的视图,可以减少渲染时间和内存消耗。
RecyclerView如何复用itemView:
RecyclerView通过ViewHolder模式来复用itemView,这是其性能优势之一。当RecyclerView需要显示新的数据时,它会首先检查是否有可重用的ViewHolder可用,如果有,则会使用这些ViewHolder,而不是创建新的。这样做可以大大减少内存消耗和布局的层级。
具体来说,RecyclerView在初始化时会创建一定数量的ViewHolder,并在需要时将它们绑定到特定的数据上。当itemView滚出屏幕时,对应的ViewHolder会被标记为可重用,并保留在内存中,以便在需要时进行重用。这样,即使有大量的数据需要显示,也只需创建足够数量的ViewHolder,而不需要为每个数据项都创建一个新的视图。
这种重用机制使得RecyclerView能够高效地处理大量数据,并在滚动时保持流畅性能,因为它不需要频繁地创建和销毁视图。
10. TCP 和 UDP 区别
1. 连接
- TCP 是面向连接的传输层协议,传输数据前先要建立连接。
- UDP 是不需要连接,即刻传输数据。
2. 服务对象
- TCP 是一对一的两点服务,即一条连接只有两个端点。
- UDP 支持一对一、一对多、多对多的交互通信
3. 可靠性
- TCP 是可靠交付数据的,数据可以无差错、不丢失、不重复、按序到达。
- UDP 是尽最大努力交付,不保证可靠交付数据。但是我们可以基于 UDP 传输协议实现一个可靠的传输协议,比如 QUIC 协议,具体可以参见这篇文章:如何基于 UDP 协议实现可靠传输?(opens new window)
4. 拥塞控制、流量控制
- TCP 有拥塞控制和流量控制机制,保证数据传输的安全性。
- UDP 则没有,即使网络非常拥堵了,也不会影响 UDP 的发送速率。
5. 首部开销
- TCP 首部长度较长,会有一定的开销,首部在没有使用「选项」字段时是
20个字节,如果使用了「选项」字段则会变长的。 - UDP 首部只有 8 个字节,并且是固定不变的,开销较小。
6. 传输方式
- TCP 是流式传输,没有边界,但保证顺序和可靠。
- UDP 是一个包一个包的发送,是有边界的,但可能会丢包和乱序。
7. 分片不同
- TCP 的数据大小如果大于 MSS 大小,则会在传输层进行分片,目标主机收到后,也同样在传输层组装 TCP 数据包,如果中途丢失了一个分片,只需要传输丢失的这个分片。
- UDP 的数据大小如果大于 MTU 大小,则会在 IP 层进行分片,目标主机收到后,在 IP 层组装完数据,接着再传给传输层。
TCP 和 UDP 应用场景:
由于 TCP 是面向连接,能保证数据的可靠性交付,因此经常用于:
FTP文件传输;- HTTP / HTTPS;
由于 UDP 面向无连接,它可以随时发送数据,再加上 UDP 本身的处理既简单又高效,因此经常用于:
TCP(Transmission Control Protocol,传输控制协议)是一种面向连接的、可靠的传输协议。在建立连接和断开连接时,TCP 需要进行三次握手和四次挥手。
三次握手(Connection Establishment):
- 客户端发送 SYN:客户端向服务器发送一个 SYN(同步)标志的数据包,表示客户端请求建立连接。
- 服务器发送 SYN-ACK:服务器收到客户端的 SYN 数据包后,会向客户端发送一个 SYN-ACK(同步-确认)标志的数据包,表示服务器收到了客户端的请求,并同意建立连接。
- 客户端发送 ACK:客户端收到服务器的 SYN-ACK 数据包后,会向服务器发送一个 ACK(确认)标志的数据包,表示客户端收到了服务器的确认,连接建立成功。
四次挥手(Connection Termination):
- 客户端发送 FIN:当客户端想要断开连接时,它向服务器发送一个 FIN(结束)标志的数据包,表示客户端不再发送数据了,但仍然可以接收数据。
- 服务器发送 ACK:服务器收到客户端的 FIN 数据包后,会向客户端发送一个 ACK 标志的数据包,表示服务器收到了客户端的请求,但服务器仍然可以向客户端发送数据。
- 服务器发送 FIN:当服务器准备好断开连接时,它向客户端发送一个 FIN 标志的数据包,表示服务器不再发送数据了,但仍然可以接收数据。
- 客户端发送 ACK:客户端收到服务器的 FIN 数据包后,会向服务器发送一个 ACK 标志的数据包,表示客户端收到了服务器的请求,连接断开成功。
挥手过程为什么是四次呢?这是因为 TCP 是全双工的,即数据可以双向传输。在断开连接时,需要分别关闭客户端到服务器和服务器到客户端的数据流。因此,需要分别发送 FIN 和 ACK,所以挥手过程是四次。这样可以确保数据的完整传输,并且在断开连接后双方都不再发送数据。
两次握手导致的问题
- 可能存在已失效的连接请求:假设客户端发送了连接请求 SYN,但由于某种原因导致该请求在网络中滞留,没有到达服务器。如果此时服务器接收不到客户端的连接请求,它就不会发送 SYN-ACK 回复。但客户端并不知道自己的连接请求是否已经到达服务器,它可能会误以为连接已经建立成功。这样就可能导致客户端和服务器之间出现已失效的连接请求,从而造成资源浪费。
- 可能出现网络中重复的连接请求:假设客户端发送了连接请求 SYN,但由于某种原因导致客户端没有收到服务器的 SYN-ACK 回复。在这种情况下,客户端会重新发送连接请求 SYN。如果之前的连接请求在网络中突然出现并到达服务器,而服务器此时又接收到了客户端的新连接请求 SYN,那么服务器可能会误认为客户端发送了两次连接请求,从而建立两个连接。这样就可能导致网络中出现重复的连接请求,产生混乱。
11. HTTP 和 HTTPS
HTTP是超文本传输协议,HTTPS是超文本传输安全协议。
HTTP协议是双向协议。
HTTPS比HTTP传输更加安全。
HTTP的状态码有哪一些

- 1XX 表示提示信息
- 2XX 表示成功
- 3XX 表示重定向
- 4XX 表示客户端错误
- 5XX 表示服务器错误
HTTP 与 HTTPS 有哪些区别?
- HTTP 是超文本传输协议,信息是明文传输,存在安全风险的问题。HTTPS 则解决 HTTP 不安全的缺陷,在 TCP 和 HTTP 网络层之间加入了 SSL/TLS 安全协议,使得报文能够加密传输。
- HTTP 连接建立相对简单, TCP 三次握手之后便可进行 HTTP 的报文传输。而 HTTPS 在 TCP 三次握手之后,还需进行 SSL/TLS 的握手过程,才可进入加密报文传输。
- 两者的默认端口不一样,HTTP 默认端口号是 80,HTTPS 默认端口号是 443。
- HTTPS 协议需要向 CA(证书权威机构)申请数字证书,来保证服务器的身份是可信的。
12. OkHttp
1.创建 OkHttpClient 对象
1 | OkHttpClient client = new OkHttpClient(); |
OkHttpClient中的构造函数:
1 | public OkHttpClient() { |
2. 发起 HTTP 请求
1 | String run(String url) throws IOException { |
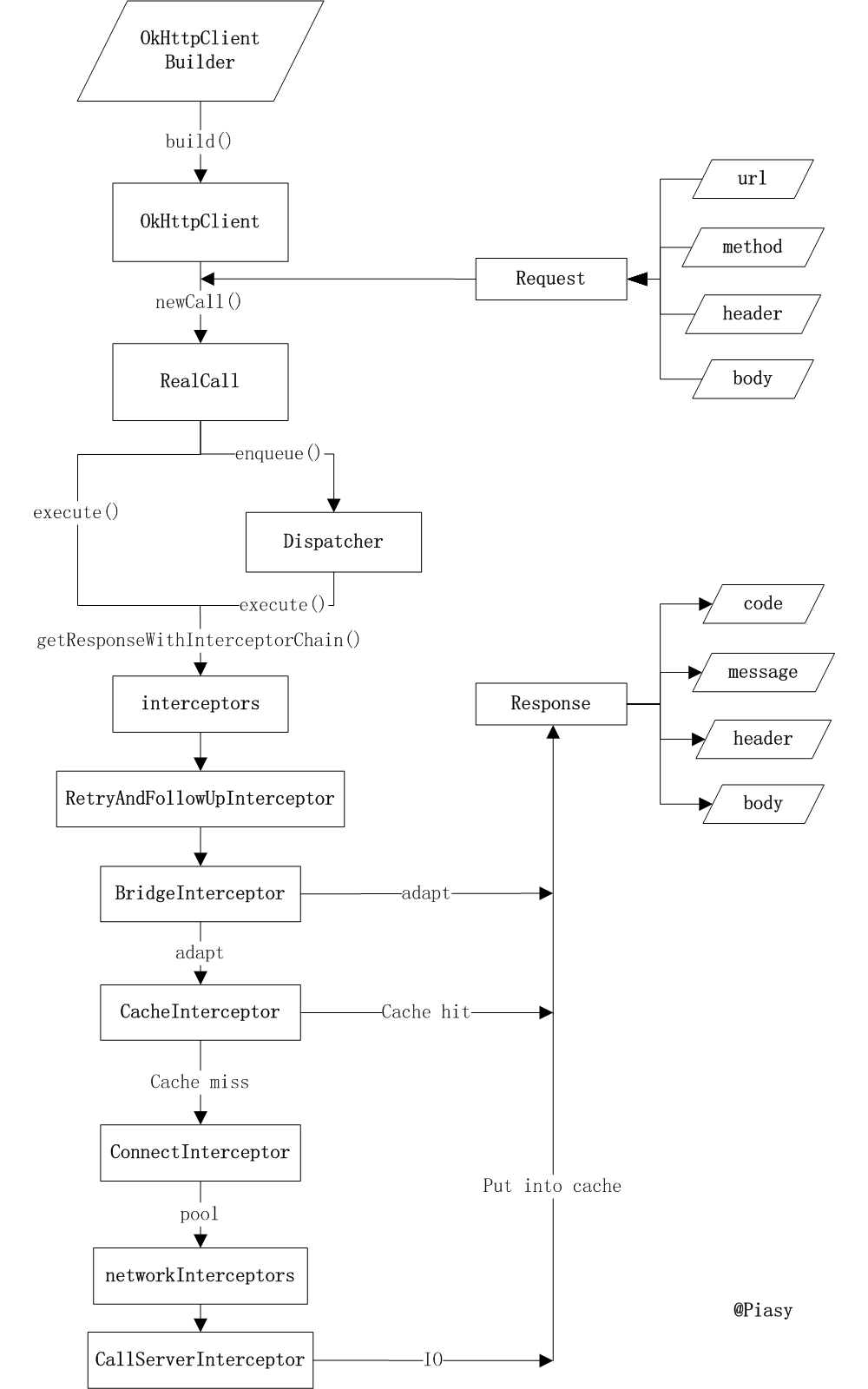
13. Retrofit
创建 Retrofit 对象
1 | Retrofit retrofit = new Retrofit.Builder() |
定义 API 并获取 API 实例
1 | public interface GitHubService { |
OkHttp和Retrofit区别
OkHttp:
- 底层网络库:OkHttp是一个强大的HTTP客户端,提供了丰富的功能来处理HTTP请求和响应,如连接池管理、请求重试、缓存等。
- 轻量级:OkHttp的设计简单,体积小巧,易于集成到Android应用中。
- 灵活性:OkHttp提供了丰富的API和扩展点,可以轻松地实现自定义的网络功能和拦截器。
- 支持HTTP/2和WebSocket:OkHttp支持HTTP/2协议和WebSocket协议,可以提供更快的网络请求和实时通讯功能。
Retrofit:
- 基于注解的声明式HTTP客户端:Retrofit是一个基于注解和接口的声明式HTTP客户端,使得定义和调用HTTP API变得更加简洁和易于理解。
- 与OkHttp配合使用:Retrofit底层使用OkHttp来处理网络请求,因此继承了OkHttp的性能优势和功能特性。
- 简化网络请求流程:Retrofit封装了网络请求的细节,使得网络请求的创建和调用变得更加简单和高效,同时支持同步和异步请求。
- 支持多种数据转换器:Retrofit支持多种数据格式的转换器,如JSON、Protobuf、Gson等,可以灵活地处理不同格式的数据。
综上所述,OkHttp和Retrofit在Android网络开发中都有着各自的优势。通常情况下,可以使用OkHttp作为底层网络库,而Retrofit作为对OkHttp的高级封装,用于简化网络请求的创建和调用。这样可以既享受OkHttp的性能和灵活性,又能够通过Retrofit简化网络请求的编写和维护
14. SharedPreferences
以键值对的形式存储和检索原始数据类型(如整数、浮点数、布尔值和字符串)。它提供了一种简单的方式来保存特定于应用程序或在应用程序之间共享的少量持久数据。
创建或访问 SharedPreferences:您可以使用
getSharedPreferences()方法获取 SharedPreferences 的实例,需要提供一个偏好文件的名称和模式(通常如果数据只能被您的应用程序访问,则使用MODE_PRIVATE)。1
SharedPreferences sharedPreferences = getSharedPreferences("my_prefs", Context.MODE_PRIVATE);
编辑 SharedPreferences:要修改偏好设置,您可以使用
edit()方法获取一个 SharedPreferences.Editor 对象。1
SharedPreferences.Editor editor = sharedPreferences.edit();
添加数据:然后,您可以使用
putInt()、putString()、putBoolean()等方法将数据添加到编辑器中。1
2
3editor.putInt("score", 100);
editor.putString("username", "JohnDoe");
editor.putBoolean("loggedIn", true);提交更改:完成更改后,需要提交以将数据持久化。
1
editor.apply();
检索数据:要从 SharedPreferences 中检索数据,您可以使用
getInt()、getString()、getBoolean()等方法。1
2
3int score = sharedPreferences.getInt("score", 0); // 如果找不到 "score",默认值为 0
String username = sharedPreferences.getString("username", "");
boolean loggedIn = sharedPreferences.getBoolean("loggedIn", false);SharedPreferences 常用于存储用户偏好、设置和其他需要在应用程序重新启动时持久化的轻量级数据。但是,需要注意的是,SharedPreferences 不应用于存储大量数据或敏感信息,因为它不是加密的,并且很容易被设备上的其他应用程序访问。对于安全或大规模数据存储,应考虑其他选项,如 SQLite 数据库或加密文件。
commit()和apply()区别
- **commit()**:
commit()方法是同步的,即它会立即将数据写入磁盘并返回写入结果(成功或失败)。因此,在调用commit()后,会阻塞调用线程直到数据写入完成。- 由于是同步操作,如果数据量较大或者磁盘IO速度较慢,可能会导致UI线程阻塞,从而影响用户体验。
- **apply()**:
apply()方法是异步的,它会将数据写入内存,然后在合适的时机(通常是在主线程空闲时)异步将数据写入磁盘,而不会阻塞调用线程。- 由于是异步操作,
apply()方法不会立即返回写入结果,因此无法知道数据是否成功写入。这意味着,即使写入失败也不会收到通知。
- **commit()**:
15.volatile 关键字的作用和原理
禁止了指令重排(指令重排是指:为了提高性能,编译器和和处理器通常会对指令进行指令重排序)
保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量值,这个新值对其他线程是立即可见的
- 这就指示JVM,这个变量是不稳定的,每次使用它都到主存中进行读取
不保证原子性
原理:volatile的原理是在生成的汇编代码中多了一个lock前缀指令,这个前缀指令相当于一个内存屏障,这个内存屏障有3个作用:
- 确保指令重排的时候不会把屏障后的指令排在屏障前,确保不会把屏障前的指令排在屏障后。
- 将当前处理器缓存行的数据写回到系统内存
- 一个处理器的缓存回写到内存会导致其他处理器的缓存失效
16. synchronized 关键字的作用
- 修饰实例方法:作用于当前对象实例加锁,进入同步代码前要获得当前对象实例的锁
- 修饰静态方法:也就是给当前类(即XXX.class对象)加锁,会作用于类的所有对象实例,因为静态成员不属于任何一个实例对象,是类成员( static 表明这是该类的一个静态资源,不管new了多少个对象,只有一份)。所以如果一个线程A调用一个实例对象的非静态 synchronized 方法,而线程B需要调用这个实例对象所属类的静态 synchronized 方法,是允许的,不会发生互斥现象,因为访问静态 synchronized 方法占用的锁是当前类的锁,而访问非静态 synchronized 方法占用的锁是当前实例对象锁
- 修饰代码块:指定加锁对象,对给定对象加锁,进入同步代码库前要获得给定对象的锁
- synchronized 可重入性(当一个线程试图操作一个由其他线程持有的对象锁的临界资源时,将会处于阻塞状态,但当一个线程再次请求自己持有对象锁的临界资源时,这种情况属于重入锁,请求将会成功)
17. String、StringBuffer、StringBuilder 的区别
- String:值是不可变的,这就导致每次对String的操作都会产生新的String对象,效率低下且浪费内存
- StringBuffer:值可变且线程安全
- StringBuilder:值可变但线程不安全,速度较StringBuffer更快
- 使用
synchronized关键字来保护它们的操作,以确保在多线程环境中只有一个线程能够访问它们的方法
18. 单例模式
1 | public class Singleton { |
1 | public static synchronized Singleton getInstance() { |
1 | public class Singleton{ |
双重检验锁模式(double checked locking pattern),是一种使用同步块加锁的方法。程序员称其为双重检查锁,因为会有两次检查 instance == null,一次是在同步块外,一次是在同步块内。为什么在同步块内还要再检验一次?因为可能会有多个线程一起进入同步块外的 if,如果在同步块内不进行二次检验的话就会生成多个实例了。
1 | public class Singleton { |
1 | public class Singleton { |
1 | public enum Singleton { |
19. ANR发生的原因及其解决办法
ANR的全称是application not responding,是指应用程序未响应,Android系统对于一些事件需要在一定的时间范围内完成,如果超过预定时间能未能得到有效响应或者响应时间过长,都会造成ANR。一般地,这时往往会弹出一个提示框,告知用户当前xxx未响应,用户可选择继续等待或者Force Close。
首先ANR的发生是有条件限制的,分为以下三点:
- 只有主线程才会产生ANR,主线程就是UI线程;
- 必须发生某些输入事件或特定操作,比如按键或触屏等输入事件,在BroadcastReceiver或Service的各个生命周期调用函数;
- 上述事件响应超时,不同的context规定的上限时间不同
- 主线程对输入事件5秒内没有处理完毕
- 主线程在执行BroadcastReceiver的onReceive()函数时10秒内没有处理完毕
- 主线程在前台Service的各个生命周期函数时20秒内没有处理完毕(后台Service 200s)
那么导致ANR的根本原因是什么呢?简单的总结有以下两点:
- 主线程执行了耗时操作,比如数据库操作或网络编程,I/O操作
- 其他进程(就是其他程序)占用CPU导致本进程得不到CPU时间片,比如其他进程的频繁读写操作可能会导致这个问题
那么如何避免ANR的发生呢或者说ANR的解决办法是什么呢?
- 避免在主线程执行耗时操作,所有耗时操作应新开一个子线程完成,然后再在主线程更新UI
- BroadcastReceiver要执行耗时操作时应启动一个service,将耗时操作交给service来完成
- 避免在Intent Receiver里启动一个Activity,因为它会创建一个新的画面,并从当前用户正在运行的程序上抢夺焦点。如果你的应用程序在响应Intent广播时需要向用户展示什么,你应该使用Notification Manager来实现








